What? Where? When?
These are key questions that every scientist or other collector of environmental data must answer.
- What is the value of the thing we are measuring?
- Where are we taking the measurement?
- When are we taking the measurement?
In a previous post we discussed how to standardize “when”. But what about “where”?
It should not be a surprise that the representation of global position is anything but standardized. Humans have been trying to keep track of this information since the time of Eratosthenes. And we have been arguing about things like the prime meridian all the way up until the International Meridian Conference of 1884. Prior to that conference, French maps would likely measure degrees east relative to the Paris Meridian — now longitude 2° 20′ 14.025″ East. (Readers of Tintin may recall Tintin’s insight in Red Rackham’s Treasure that old French navigational charts used the Paris Meridian and not Greenwich.)
Now that the prime meridian has been sorted out, in what other ways can the latitudes and longitudes in data files be incompatible? It turns out there are several incompatible ways to represent latitudes and longitudes as text strings:
- lats and lons as degrees-minutes-seconds
- lats and lons as degrees-decimal minutes
- lats and lons as decimal degrees
- longitudes with W longitudes positive
- longitudes with W longitudes negative
Scalars vs. Vectors
The disagreement on whether longitudes W are positive or negative numbers belies a deeper confusion about whether longitude is a scalar or a vector. In freshman physics we learn that scalars measure magnitude whereas vectors measure magnitude and direction. So “-90 degrees longitude” is a scalar (minus ninety units along an axis with zero at the prime meridian); while “90 degrees West” is a vector (90 units from the start in a Westward direction). This same confusion also occurs in oceanography and atmospheric science where they often store “depth” and “height” as two separate measurements, both with positive numbers.
Physicists, who understand the difference between scalars and vectors, would of course insist that we throw out “depth” and “height” entirely and instead use ρ — distance from the center of the Earth. They would also replace latitude and longitude with φ and θ and measure each in radians. But this seems an impractical solution. We will be happy if we can convince people that measurements should be reported as “-90” rather than “90W”. Physicists will need to be satisfied that this convention and the right hand rule place the Northern hemisphere on top where it was meant it to be. 😉
Standard Representations
It seems an appropriate time to suggest a standard representation against which the latitudes and longitudes in a dataset can be validated. Naturally we look to the International Organization for Standardization for a suggestion. Their best effort to date is ISO 6709 which misses the mark by a mile. Rather than insist on a single representation, they try to accommodate many. And, by combining latitude and longitude into a single format they preclude any possibility of treating latitude or longitude as a simple, numeric value that can be interpreted by software that might actually place the location on a map.
No, we are looking for something simpler that can be used with plotting or mapping software; something that would make it easy, for example, to convert latitudes and longitudes found in a CSV file into the KML needed to display locations on Google Earth for example.
A Reasonable Standard
We will make a bold proposal for a new standard consisting of a few simple suggestions:
- Latitudes should be stored as numeric values with units of decimal degrees on the domain -90:90 with negative values in the Southern hemisphere.
- Longitudes should be stored as numeric values with units of decimal degrees on the domain -180:180 with negative values in the Western hemisphere.
For those out there wishing to retain the existing representations in raw data files for use with older software we additionally recommend:
- Whenever a non-conforming “latitude” or “longitude” field already exists in a dataset, add a new “latitude_dd” or “longitude_dd” field for the new, standardized representation.
We dream of a day when those working to make datasets more findable will devote some of their considerable energy and talent to also making the data in those datasets more uniform and more reliable, in short — more useful.
It doesn’t seem that hard really.
Validating Longitudes and Latitudes
As an example of incomplete data management, we will use CSV files from the Recreation Information Database (RIDB) which brings together information about recreational sites from across government agencies. This is an extremely laudable goal and was without doubt a challenging task. But the end result falls short when it comes to the final results. While data managers appear to have converted all latitudes and longitudes into numeric decimal degrees, there are still a few longitudes that are apparently encoded as “degrees W” rather than “degrees E” as well as some latitudes that are … how shall we say it … implausible. The R code below demonstrates the problems.
# Use standard tidyverse tools
library(readr)
library(dplyr)
library(maps)
----- Download and unzip files -----
zipFile <- file.path(tempdir(), "RIDBFullExport_V1_CSV.zip")
download.file(
url = "https://ridb.recreation.gov/downloads/RIDBFullExport_V1_CSV.zip",
destfile = zipFile
)
# trying URL
# 'https://ridb.recreation.gov/downloads/RIDBFullExport_V1_CSV.zip'
# Content type 'application/zip' length 173491403 bytes (165.5 MB)
# ==================================================
# downloaded 165.5 MB
unzip(zipFile)
----- Read in data -----
# The "Facility" dataset has some longitude/latitude problems
# > list.files(pattern = "^Facil")
# [1] "Facilities_API_v1.csv" "FacilityAddresses_API_v1.csv"
Facilities <- readr::read_csv("Facilities_API_v1.csv")
# Parsed with column specification:
# cols(
# .default = col_character(),
# LegacyFacilityID = col_double(),
# OrgFacilityID = col_double(),
# ParentOrgID = col_double(),
# ParentRecAreaID = col_double(),
# FacilityLongitude = col_double(),
# FacilityLatitude = col_double(),
# Reservable = col_logical(),
# Enabled = col_logical(),
# LastUpdatedDate = col_date(format = "")
# )
# See spec(…) for full column specifications.
# Warning: 3658 parsing failures.
FacilityAddresses <- readr::read_csv("FAcilityAddresses_API_v1.csv")
# Parsed with column specification:
# cols(
# FacilityAddressID = col_character(),
# FacilityID = col_double(),
# FacilityAddressType = col_character(),
# FacilityStreetAddress1 = col_character(),
# FacilityStreetAddress2 = col_character(),
# FacilityStreetAddress3 = col_character(),
# City = col_character(),
# PostalCode = col_character(),
# AddressStateCode = col_character(),
# AddressCountryCode = col_character(),
# LastUpdatedDate = col_date(format = "")
# )
----- Validate locations -----
maps::map('world')
points(
Facilities$FacilityLongitude,
Facilities$FacilityLatitude,
pch = 15, col = 'red', cex = 0.5
)
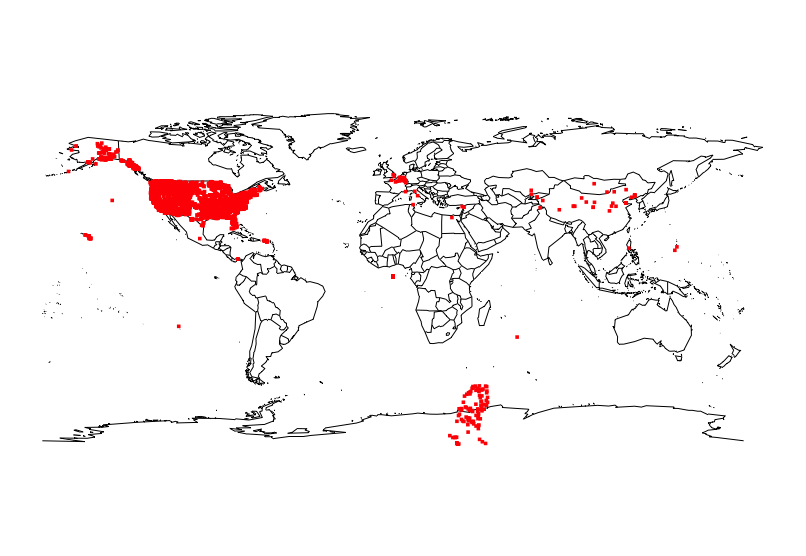
Lots of facilities in the US including Hawaii, Puerto Rico, Guam. Some other locations in Europe and the Philippines might be military bases. But what’s up with locations in China? Or that blob of locations in/near Antarctica?
We will continue our validation by looking up these “Chinese” locations.
# Find FacilitiyIDs that appear near China
ids <-
Facilities %>%
filter(
FacilityLongitude > 70,
FacilityLongitude < 140,
FacilityLatitude > 20
) %>%
pull(FacilityID)
# Check on the addresses of these facilities
FacilityAddresses %>%
filter(FacilityID %in% ids) %>%
select(
City,
PostalCode,
AddressStateCode,
AddressCountryCode
)
# # A tibble: 45 x 4
# City PostalCode AddressStateCode AddressCountryCode
#
# 1 Jasper AR 72641 USA
# 2 New NY 10005 USA
# 3 Fort Payne AL 35967 USA
# 4 Buxton NC 27920 USA
# 5 Manteo NC 27954 USA
# 6 Quincy MA 02169 USA
# 7 Quincy MA 02169 USA
# 8 Arco ID 83213 USA
# 9 Arco ID 83213 USA
# 10 La Junta CO 81050 USA
# # … with 35 more rows
Two problems are immediately apparent:
1. Column names PostalCode and AddressStateCode are swapped
2. The longitudes associated with these facilities appear to be “W” rather than “E” and need to be negated.
We hope that this demonstration points out the need to have end users — those wishing to create maps or graphs — working alongside the software developers to ensure that any location data going into compilations are properly validated. Data validation is not an optional “add-on”. It is a core feature of any serious data management project.
